FlyWay
download : https://flywaydb.org
some commands:
>flyway info 'latest status of db
>flyway repair 'for any error, it repairs
>flyway clean - delete whole schema. to do it:
>git checkout flyway.conf
>vi flyway.conf
> flyway.cleanDisabled=false(after clean, write back to true)
>flyway migrate 'for update with the latest status *****************
>flyway baseline
Why database migrations?
First, let's start from the beginning and assume we have a project called Shiny and its primary deliverable is a piece of software called Shiny Soft that connects to a database called Shiny DB.
The simplest diagram to represent this could look something like this:

We have our software and our database. Great. And this could very well be all you need.
But on most projects, this simple view of the world very quickly translates into this:
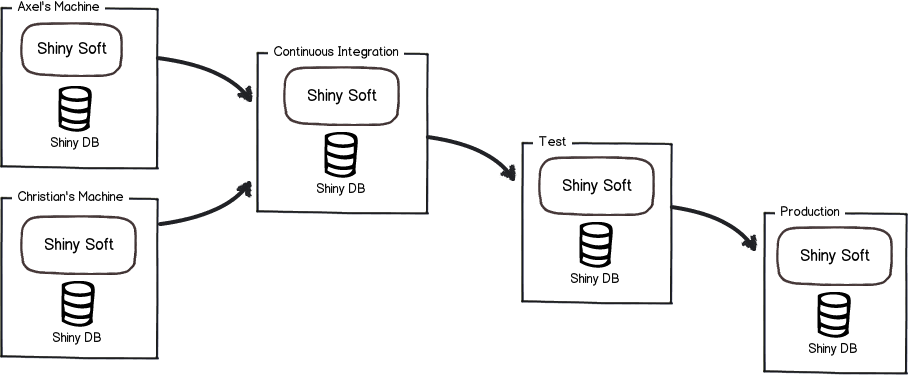
We now not only have to deal with one copy of our environment, but with several. This presents a number of challenges.
We have been pretty good at solving them on the code side.
- Version control is now universal with better tools everyday.
- We have reproducible builds and continuous integration.
- We have well defined release and deployment processes.
But what about the database?

Well unfortunately we have not been doing so well there. Many projects still rely on manually applied sql scripts. And sometimes not even that (a quick sql statement here or there to fix a problem). And soon many questions arise:
- What state is the database in on this machine?
- Has this script already been applied or not?
- Has the quick fix in production been applied in test afterwards?
- How do you set up a new database instance?
- More often than not the answer to these questions is: We don't know.
Database migrations are a great way to regain control of this mess.
They allow you to:
- Recreate a database from scratch
- Make it clear at all times what state a database is in
- Migrate in a deterministic way from your current version of the database to a newer one
How Flyway works
The easiest scenario is when you point Flyway to an empty database.
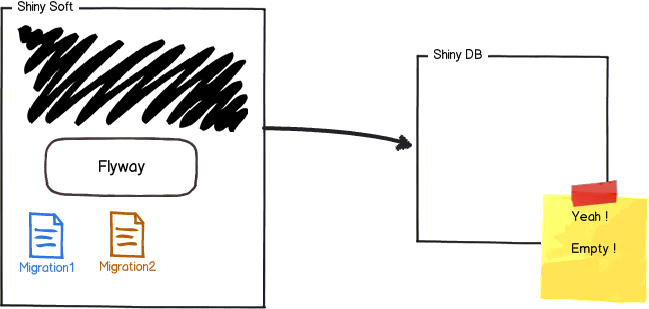
It will try to locate its schema history table. As the database is empty, Flyway won't find it and will create it instead.
You now have a database with a single empty table called flyway_schema_history by default:
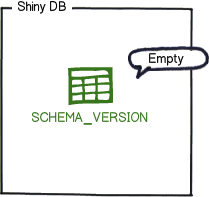
This table will be used to track the state of the database.
Immediately afterwards Flyway will begin scanning the filesystem or the classpath of the application for migrations. They can be written in either Sql or Java.
The migrations are then sorted based on their version number and applied in order:
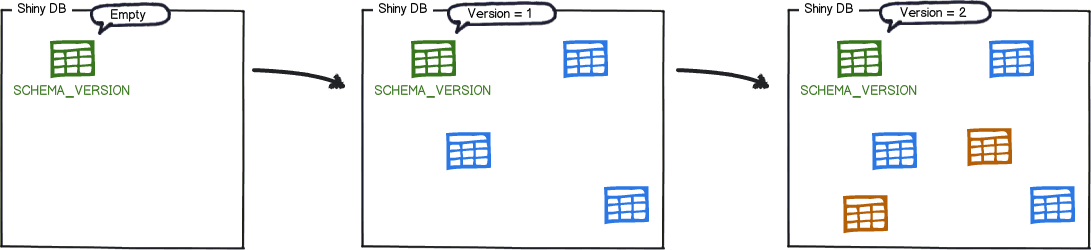
As each migration gets applied, the schema history table is updated accordingly
With the metadata and the initial state in place, we can now talk about migrating to newer versions.
Flyway will once again scan the filesystem or the classpath of the application for migrations. The migrations are checked against the schema history table. If their version number is lower or equal to the one of the version marked as current, they are ignored.
The remaining migrations are the pending migrations: available, but not applied.
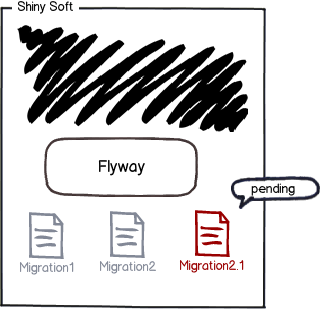
They are then sorted by version number and executed in order:
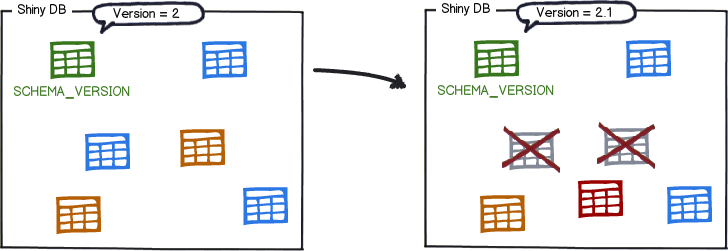
And that's it! Every time the need to evolve the database arises, whether structure (DDL) or reference data (DML), simply create a new migration with a version number higher than the current one. The next time Flyway starts, it will find it and upgrade the database accordingly.