Difference between revisions of "Collections"
| (4 intermediate revisions by the same user not shown) | |||
| Line 5: | Line 5: | ||
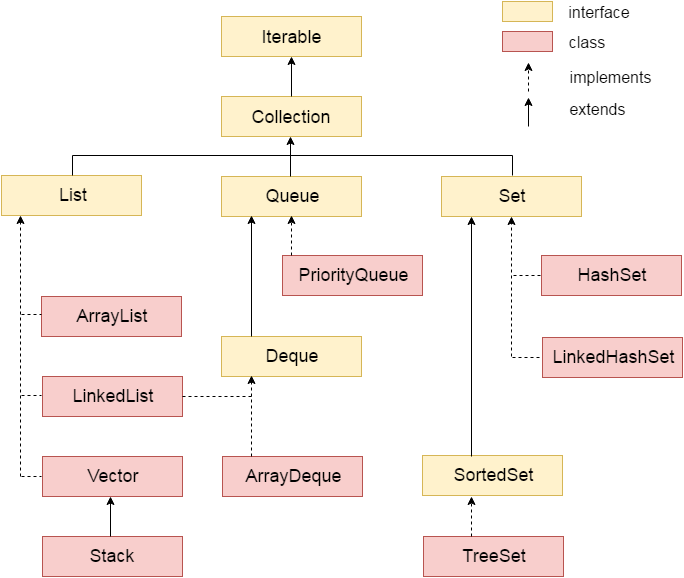
Java Collection simply means a single unit of objects. Java Collection framework provides many interfaces ([[Set]], [[List]], [[Queue]], [[Deque]] etc.) and classes ([[ArrayList]], [[Vector]], [[LinkedList]], [[PriorityQueue]], [[HashSet]], [[LinkedHashSet]], [[TreeSet]] etc). | Java Collection simply means a single unit of objects. Java Collection framework provides many interfaces ([[Set]], [[List]], [[Queue]], [[Deque]] etc.) and classes ([[ArrayList]], [[Vector]], [[LinkedList]], [[PriorityQueue]], [[HashSet]], [[LinkedHashSet]], [[TreeSet]] etc). | ||
| − | Hashtable, Vector, | + | *'''thread-safe?''' [[Vector]], [[Hashtable]], [[Properties]] and [[Stack]] are synchronized classes, so they are thread-safe and can be used in multi-threaded environment. |
| + | *You can get a synchronized version of a Java Collection with '''Collections.synchronizedCollection(Collection<T> c)''' | ||
| + | *Java Collections have come through a long way with usage of '''Generics''' and '''Concurrent Collection''' classes for '''thread-safe''' operations. | ||
| + | *'''Generics''' allow us to '''provide the type of Object''' that a collection can contain, so if you try to add any element of other type it throws compile time error. | ||
| + | *[[Enumeration]] is '''twice as fast as Iterator''' and uses very '''less memory'''. | ||
| + | *'''fail-fast''' :Iterator fail-fast property '''checks for any modification''' in the structure of the underlying collection everytime we try to get the next element. If there are any modifications found, it throws '''ConcurrentModificationException'''. | ||
| + | *all the collection classes in '''java.util package are fail-fast''' whereas collection classes in '''java.util.concurrent are fail-safe'''. | ||
| + | *'''ArrayList and LinkedList?''' ArrayList is an index based, but LinkedList stores data as list of nodes. Insertion, addition or removal of an element is faster in LinkedList compared to ArrayList. LinkedList consumes more memory than ArrayList | ||
| + | *[[Queue]] and [[Stack]]:Queue -> FIFO, Stack -> LIFO, Stack is a '''class''' that extends Vector whereas Queue is an '''interface''' | ||
| + | *'''How HashMap works''': | ||
| + | <source> | ||
| + | HashMap stores key-value pair in Map.Entry static nested class implementation. HashMap works on hashing algorithm and uses hashCode() and equals() method in put and get methods. | ||
| + | |||
| + | When we call put method by passing key-value pair, HashMap uses Key hashCode() with hashing to find out the index to store the key-value pair. The Entry is stored in the LinkedList, so if there are already existing entry, it uses equals() method to check if the passed key already exists, if yes it overwrites the value else it creates a new entry and store this key-value Entry. | ||
| + | |||
| + | When we call get method by passing Key, again it uses the hashCode() to find the index in the array and then use equals() method to find the correct Entry and return it’s value. Below image will explain these detail clearly. | ||
| + | </source> | ||
| + | |||
| + | *'''What is the importance of hashCode() and equals() methods?''' | ||
| + | <source> | ||
| + | HashMap uses Key object hashCode() and equals() method to determine the index to put the key-value pair. These methods are also used when we try to get value from HashMap. If these methods are not implemented correctly, two different Key’s might produce same hashCode() and equals() output and in that case rather than storing it at different location, HashMap will consider them same and overwrite them. | ||
| + | |||
| + | Similarly all the collection classes that doesn’t store duplicate data use hashCode() and equals() to find duplicates, so it’s very important to implement them correctly. The implementation of equals() and hashCode() should follow these rules. | ||
| + | |||
| + | If o1.equals(o2), then o1.hashCode() == o2.hashCode()should always be true. | ||
| + | If o1.hashCode() == o2.hashCode is true, it doesn’t mean that o1.equals(o2) will be true. | ||
| + | </source> | ||
| + | |||
Latest revision as of 04:16, 5 November 2018
Collections in java is a framework that provides an architecture to store and manipulate the group of objects.
All the operations that you perform on a data such as searching, sorting, insertion, manipulation, deletion etc. can be performed by Java Collections.
Java Collection simply means a single unit of objects. Java Collection framework provides many interfaces (Set, List, Queue, Deque etc.) and classes (ArrayList, Vector, LinkedList, PriorityQueue, HashSet, LinkedHashSet, TreeSet etc).
- thread-safe? Vector, Hashtable, Properties and Stack are synchronized classes, so they are thread-safe and can be used in multi-threaded environment.
- You can get a synchronized version of a Java Collection with Collections.synchronizedCollection(Collection<T> c)
- Java Collections have come through a long way with usage of Generics and Concurrent Collection classes for thread-safe operations.
- Generics allow us to provide the type of Object that a collection can contain, so if you try to add any element of other type it throws compile time error.
- Enumeration is twice as fast as Iterator and uses very less memory.
- fail-fast :Iterator fail-fast property checks for any modification in the structure of the underlying collection everytime we try to get the next element. If there are any modifications found, it throws ConcurrentModificationException.
- all the collection classes in java.util package are fail-fast whereas collection classes in java.util.concurrent are fail-safe.
- ArrayList and LinkedList? ArrayList is an index based, but LinkedList stores data as list of nodes. Insertion, addition or removal of an element is faster in LinkedList compared to ArrayList. LinkedList consumes more memory than ArrayList
- Queue and Stack:Queue -> FIFO, Stack -> LIFO, Stack is a class that extends Vector whereas Queue is an interface
- How HashMap works:
HashMap stores key-value pair in Map.Entry static nested class implementation. HashMap works on hashing algorithm and uses hashCode() and equals() method in put and get methods.
When we call put method by passing key-value pair, HashMap uses Key hashCode() with hashing to find out the index to store the key-value pair. The Entry is stored in the LinkedList, so if there are already existing entry, it uses equals() method to check if the passed key already exists, if yes it overwrites the value else it creates a new entry and store this key-value Entry.
When we call get method by passing Key, again it uses the hashCode() to find the index in the array and then use equals() method to find the correct Entry and return it’s value. Below image will explain these detail clearly.- What is the importance of hashCode() and equals() methods?
HashMap uses Key object hashCode() and equals() method to determine the index to put the key-value pair. These methods are also used when we try to get value from HashMap. If these methods are not implemented correctly, two different Key’s might produce same hashCode() and equals() output and in that case rather than storing it at different location, HashMap will consider them same and overwrite them.
Similarly all the collection classes that doesn’t store duplicate data use hashCode() and equals() to find duplicates, so it’s very important to implement them correctly. The implementation of equals() and hashCode() should follow these rules.
If o1.equals(o2), then o1.hashCode() == o2.hashCode()should always be true.
If o1.hashCode() == o2.hashCode is true, it doesn’t mean that o1.equals(o2) will be true.
Contents
Methods of Collection interface
There are many methods declared in the Collection interface. They are as follows:
| No. | Method | Description |
|---|---|---|
| 1 | public boolean add(Object element) | is used to insert an element in this collection. |
| 2 | public boolean addAll(Collection c) | is used to insert the specified collection elements in the invoking collection. |
| 3 | public boolean remove(Object element) | is used to delete an element from this collection. |
| 4 | public boolean removeAll(Collection c) | is used to delete all the elements of specified collection from the invoking collection. |
| 5 | public boolean retainAll(Collection c) | is used to delete all the elements of invoking collection except the specified collection. |
| 6 | public int size() | return the total number of elements in the collection. |
| 7 | public void clear() | removes the total no of element from the collection. |
| 8 | public boolean contains(Object element) | is used to search an element. |
| 9 | public boolean containsAll(Collection c) | is used to search the specified collection in this collection. |
| 10 | public Iterator iterator() | returns an iterator. |
| 11 | public Object[] toArray() | converts collection into array. |
| 12 | public boolean isEmpty() | checks if collection is empty. |
| 13 | public boolean equals(Object element) | matches two collection. |
| 14 | public int hashCode() | returns the hashcode number for collection. |
Iterator interface
Iterator interface provides the facility of iterating the elements in forward direction only.
Methods of Iterator interface
There are only three methods in the Iterator interface. They are:
| No. | Method | Description |
|---|---|---|
| 1 | public boolean hasNext() | It returns true if iterator has more elements. |
| 2 | public Object next() | It returns the element and moves the cursor pointer to the next element. |
| 3 | public void remove() | It removes the last elements returned by the iterator. It is rarely used. |
Set
EnumSet
HashSet
LinkedHashSet
TreeSet
SortedSet
List
ArrayList
LinkedList
Vector
Stack
Queue
PriorityQueue
Deque
ArrayDeque
Map
HashMap
LinkedHashMap
IdentityHashMap
WeakHashMap
SortedMap
TreeMap
Generics
Big O Notation
Big O is the way of measuring the efficiency of an algorithm and how well it scales based on the size of the dataset. Imagine you have a list of 10 objects, and you want to sort them in order. There’s a whole bunch of algorithms you can use to make that happen, but not all algorithms are built equal. Some are quicker than others but more importantly the speed of an algorithm can vary depending on how many items it’s dealing with. Big O is a way of measuring how an algorithm scales. Big O references how complex an algorithm is.
Collection Interview Questions and Answers
How HashMap works internally ?
HashMap works on the principle of Hashing. To understand Hashing , we should understand the three terms first
- Hash Function
- Hash Value
- Bucket
What is Hash function?
hashCode() method which returns an integer value is the Hash function. The important point to note that, this method is present in Object class.
This is the code for the hash function(also known as hashCode method) in Object Class :
public native int hashCode();What is Hash value?
HashCode method return an int value.So the Hash value is just that int value returned by the hash function.
What is bucket?
A bucket is used to store key value pairs. A bucket can have multiple key-value pairs. In hash map, bucket used is simply a linked list to store objects.
So how does hashMap works internally?
We know that Hash map works on the principle of hashing which means
HashMap get(Key k) method calls hashCode method on the key object and applies returned hashValue to its own static hash function to find a bucket location(backing array)
What if when two keys are same and have the same HashCode?
If key needs to be inserted and already inserted hashkey’s hashcodes are same, and keys are also same(via reference or using equals() method) then override the previous key value pair with the current key value pair. The other important point to note is that in Map ,Any class(String etc.) can serve as a key if and only if it overrides the equals() and hashCode() method.
What is collision in HashMap?
Collisions happen when 2 distinct keys generate the same hashCode() value. Multiple collisions are the result of bad hashCode() algorithm.
The more the collisions the worse the performance of the hashMap.
There are many collision-resolution strategies – chaining, double-hashing, clustering.
However, java has chosen chaining strategy for hashMap, so in case of collisions, items are chained together just like in a linkedList.